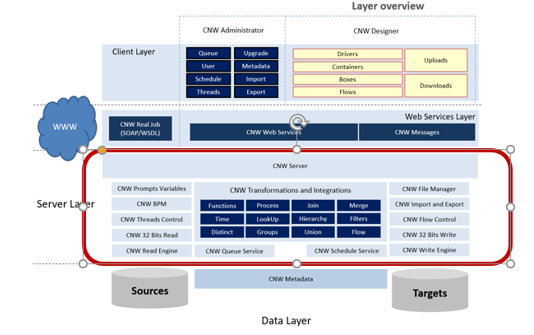
Server
O PIS Server é o módulo que recebe e envia as requisições de comunicação entre o cliente e o servidor através do PIS Web Service. Sobre sua gerência estão todos os módulos de inteligência do produto. É através dos módulos contidos no PIS Server que o produto irá funcionar e executar seus processos.
Ref.000008
PIS READ AND WRITE ENGINE
O servidor do PIS possui um mecanismo de leitura de dados especializado para cada tipo de fonte.
Podemos destacar o mecanismo de leitura em banco de dados via ODBC, ou diretamente usando ADO.NET no Microsoft SQL SERVER, Oracle, MySQL, PostgreSQL e outros mais.
Mas podemos destacar também leitura de dados de arquivos textos, planilhas de Excel, arquivos no formato XML e arquivos no formato JSON. Estes arquivos podem estar em diretório do servidor, em sites FTP ou em páginas HTTP.
Porém é possível ler dados através de WEB SERVICES, no padrão RESTFUL ou SOAP. Também podemos ler de bancos de dados não estruturados (NOSQL) como MongoDB, de bancos ERP como Protheus TOTVS, bases multidimensionais como Microsoft OLAP Services ou SAP BW e bases especialistas como EXACT.
É possível a equipe de desenvolvimento customizar, sobre medida, algum tipo de driver de leitura especial para um tipo de fonte de dados não mapeado anteriormente.
PIS Write Engine. Aqui temos o componente que escreve o dado na fonte destino. Neste caso, quase todas as fontes onde podemos ler dados também podemos escrever. Foi destacado a palavra “quase” porque em nem todas as fontes de dados devemos poder escrever. Um caso específico é quando a fonte de dados destino é um ERP com suas tabelas especialistas.
Mas, para os bancos de dados relacionais Microsoft SQL Server, Oracle, MySQL e PostgreSQL, o mecanismo de escrita possui uma inteligência onde, por exemplo, baseado numa chave primária, o PIS poderá saber se inclui uma linha nova, substitui ou apaga uma linha existente.
Também há mecanismos de leituras em lotes para que, quando necessário, leituras de muitos registros possam ser feitas num tempo reduzido. Durante o mecanismo de configuração do processo de escrita, estas políticas de carga poderão ser configuradas.
Mas a escrita de dados também pode ser efetuada no formato de arquivo texto, JSON, Excel ou XML. É possível enviar estes arquivos para uploads em sites FTP, HTTP ou enviá-los via Web Services para outros ambientes.
PIS 32 BITS READ AND WRITE.
O PIS é uma ferramenta 64 bits. Mas podemos encontrar bancos de dados cujos drivers de comunicação sejam de 32 bits. Para isso temos um módulo especial que faz esta leitura para estes casos. Para o usuário que desenha e executa os processos de integração, o gerenciamento se estamos lendo de 64 bits ou de 32 fica automático, desde que devidamente configurada nas propriedades do desenho do processo de ETL ou Integração.
O PIS 32 Bits Write faz o mesmo processo que o de leitura escrevendo em bases de dados 32 bits de forma transparente.
PIS THREADS CONTROL.
Todo o processo de ETL ou integração desenhados pelo PIS, ao seu executado, é redirecionado a uma Thread. A Thread é um processo único e independente que ocorre no servidor. Pode ser que um processo execute diversas Threads, de forma sequencial ou em paralelo. Também podemos ter, num único servidor, várias Threads de vários processos sendo executados ao mesmo tempo.
O PIS Threads Control controla todos estes processos. Por um painel de controle é possível ver quais Threads estão sendo executadas, o seu tempo estimado de término, se a Thread executou o processo com sucesso ou erro, possibilita visualizar o log do processamento de uma Thread bem como “derrubar” uma Thread que está sendo processada.
PIS BPM.
Através do PIS BPM podemos acompanhar estatísticas dos dados que estão sendo lidos. Isso faz com que possamos entender se nossa extração de dados está correta ou não.
PIS PROMPT VARIABLES.
O PIS Prompt Variables consiste na possibilidade de criar variáveis para execução ou configuração de qualquer processo ou componente do PIS. Podemos, por exemplo, criar uma variável (Prompt) que representa o local onde um arquivo vai ser gravado, ou representa o nome da tabela em que o dado deve ser lido, ou no número de linhas que serão escritas num arquivo texto. Qualquer configuração ou parâmetro de qualquer componente do PIS pode ser substituído por uma Prompt Variable.
Nestas variáveis podem ser atribuídos valores únicos, ou vetores (Para criação de loopings), associadas a uma função ou fórmula ou associar o conjunto de valores de uma Prompt Variable ao resultado de uma consulta a uma fonte de dados. Digamos que desejamos ler dados de um conjunto de cidades. Esta lista de cidades pode ser uma Prompt Variable baseada em uma tabela em um banco de dados.
Dependendo da forma com que as Prompts Variables são criadas podemos criar templates de integração e aplicá-los em ambientes diferentes, desde que estes processos sejam semelhantes. Isso aumenta consideravelmente a produtividade quando da implementação de processos de integração em sistemas semelhantes em locais diferentes.
PIS FILE MANAGER.
O PIS File Manager é o módulo de comunicação com a parte cliente que gerencia e armazena os arquivos que foram transportados pelo cliente através do Upload ou enviar arquivos de volta através do processo de Download.
PIS IMPORT/EXPORT.
Durante o desenvolvimento de um projeto de integração e ETL podemos encontrar diversos cenários de implementação: Podemos ter a construção dos processos num ambiente de desenvolvimento que, depois, é transportado para um de testes e finalmente disponibilizado em produção. Ou então podemos desenvolver uma integração como se fosse um template e depois publicá-la em outro ambiente que utilize processos semelhantes (Mencionamos isso quando falamos de Prompt Variables). Mais ainda. É possível que seja necessário criar backups dos modelos e recuperá-los em seguida. Seja para prevenir possíveis perdas seja para criar um repositório de versões de modelos.
Toda esta transferência de ambientes pode ser executada com o PIS Import Export. Com este módulo podemos sincronizar modelos de ambientes distintos. Ele possui a possibilidade de preservar particularidades no ambiente que está sendo restaurado, como variáveis de ambiente e propriedades de conexão nas fontes de dados. Também pode efetuar a sincronização de ambientes não somente incluindo ou alterando objetos entre os ambientes como também apagando objetos no ambiente destino que foram, posteriormente, apagados no ambiente fonte.
PIS FLOW.
O PIS Flow irá construir um fluxo lógico para a execução das Threads. Na verdade, uma Thread consiste na execução do que chamamos de Boxes. Quando um Box for executado ele é direcionado para uma instância do processador do servidor (Thread) que irá ser executada utilizando determinados recursos de máquina (Hardware) para fazer aquilo que foi especificado no desenho do modelo.
É neste módulo que iremos determinar a sequência de execução dos Boxes. Podemos determinar a execução em forma sequencial, usar desvios de execução (Se uma Thread de um Box der erro faça uma coisa. Se der certo faça outra), criar loopings para execução de um ou mais grupos de Boxes, criar subfluxos (Sub Flows) para executar um conjunto de Boxes de forma repetida, esperar um evento acontecer para iniciar o processamento de um Box e muito mais.
É neste ponto que a execução dos Fluxos é agendada. Podemos agendar sua execução para ser realizada em um horário específico, ou executar diversas vezes no dia (Exemplo: Executar a cada 1 minuto) ou executar em looping eternamente, ou durante um intervalo de tempo. Podemos agendar a execução para um ou mais dias na semana, no mês ou para alguns meses do ano.
PIS QUEUE SERVICE.
Um dos serviços responsáveis pelo ambiente do PIS é o Thread Services (Na figura representamos como Queue Service, mas é a mesma coisa). Este serviço fica observando a fila de processos a serem executados. Quando algum processo entra na fila, o serviço o pega e redireciona para um recurso de máquina (Hardware) para que seja executado. O processo pode entrar nesta fila através de uma ordem manual de um usuário ou através do PIS Schedule Service.
Durante as execuções dos processos, os mesmos podem ser observados através do PIS Thread Monitor. Nele podemos: Derrubar processos indesejáveis, acompanhar o processamento de um processo no seu detalhe, verificar logs a fim de detectar erros e apagar logs antigos.
PIS SCHEDULE SERVICE.
PIS Schedule Service: Aqui temos um outro serviço do servidor que executa processos baseados em um agendamento. Este serviço não executa especificamente o processo. Na verdade, ele transporta para a fila de processos, a mesma que é observada pelo PIS Threads Services, o processo num determinado dia e hora. Depois o serviço é que vai executá-lo respeitando esta fila.
Os processos podem ser agendados num determinado dia e hora, em determinados dias do mês, dias da semana e inclusive em apenas alguns meses do ano. Pode ser executado repetindo o processo periodicamente a cada número de segundos e durante um determinado período. Também todos os agendamentos podem ter um período de validade.
PIS TRANSFORMATIONS AND INTEGRATIONS.
Aqui se encontra o motor dos processos de ETL e integração. Através do PIS Transformations é que o dado será modificado para ser armazenado na fonte de dados destinada ao formato correto.
Muitos módulos e processos de transformação podem ser implementados. Vamos mencionar alguns deles a seguir:
- Funções de transformações – Existe um vasto catálogo de funções de transformações categorizados por funções de manipulação de textos, datas, números, tabelas, funções de sistema operacional, geração de códigos aleatórios e funções especiais relacionadas com cálculos e validações de formatos de códigos.
- Funções especiais – Porém, se nenhuma função do catálogo atender a necessidade do processo de integração ou ETL é possível criar suas próprias funções de transformações através de um IDE de desenvolvimento (Dentro do próprio PIS) ou importar códigos de programas do Visual Studio .NET para atender as necessidades de transformações. Este módulo permite adicionar DLLs externas que possuam inteligência de negócio e enriquecer suas próprias funções.
- Funções de processamento - Possui o mesmo princípio das funções especiais, mas, aqui, em vez do resultado ser um determinado valor, texto ou data, nelas, o resultado é uma expressão lógica (Verdadeiro ou falso). Usamos as funções de processamento para testar e fazer desvios lógicos no fluxo de execução do processo de integração ou ETL bem como para executar processos de manipulação de dados mais complexos.
- Time Intelligence – São transformações que montam calendários baseados em datas que sejam previamente estipuladas ou baseadas em dados contidos na origem ou destino. Podemos estipular datas no calendário gregoriano, obtendo pontos de consolidação (Semana, mês, bimestre, semestre, ano, etc.) ou trabalhar com calendários Hindu, Islam ou Lunar.
- Hierarquias – Algumas transformações são dedicadas a montar ou desmontar hierarquia. Elas podem transformar uma hierarquia desnormalizada de uma tabela num formato Parent-Children ou vice-versa. Também podem implementar, de maneira automática, os processos de Lookup para criação de códigos sequenciais, ou no formato texto, em dimensões de Data warehouses.
- Processos de manipulação de tabelas como : Inclusão e exclusão de novas colunas, inclusão de novas linhas, criação de novas colunas usando fórmulas matemáticas e expressões lógicas, efetuar o ordenamento de dados, criar chaves primárias, testar integridade dos dados baseado em uma chave estrangeira, efetuar união de tabelas, ligação entre tabelas, apresentar o distinto de linhas da tabela, fazer grupamento usando critério de somas, máximos, mínimos e médias, criar processos condicionais e muitos outras mais não mencionadas aqui.